
Download Large Jupyter Workspace files
Recently, we were working on a Jupyter Workspace at anyscale-training.com/jupyter/lab. As there was no option to download all files of the workspace nor there was a way to create an archive from the GUI, we followed the procedure below (that we also use on Coursera.org and works like a charm):
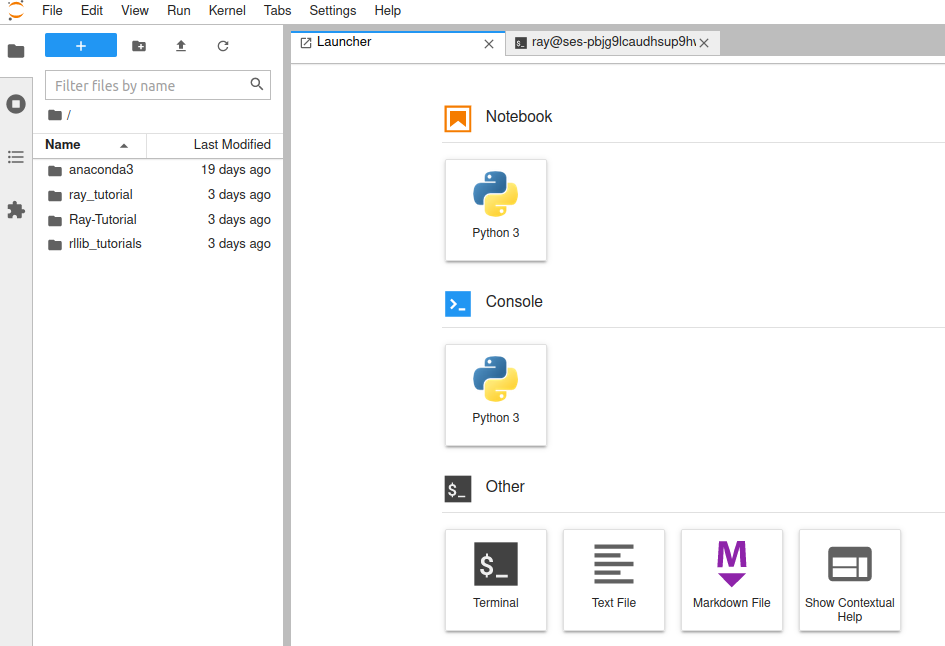
First, we clicked on the blue button with the + sign in it.
That opened the Launcher tab that is visible on the image above.
From there, we clicked on the Terminal button under the Other category.
In the terminal, we executed the following command to create a compressed archive of all the files we needed to download:
tar -czf Ray-RLLib-Tutorials.tar.gz ray_tutorial/ Ray-Tutorial/ rllib_tutorials/;
After the command completed its execution, we could see our archive on the left list of files. By right-clicking it we we are able to initiate its download. Unfortunately, after the first 20MB the download would always crash! To fix this issue, we split the archive to multiple archives of 10MB each, then downloaded them individually and finally merged them back together on our PC. The command to split the compressed archive to multiple smaller archives of fixed size was the following:
tar -czf - ray_tutorial/ Ray-Tutorial/ rllib_tutorials/ | split --bytes=10MB - Ray-RLLib-Tutorials.tar.gz.;

After downloading those files one by one by right-clicking on them and then selecting the Download option we recreated the original structure on our PC using the following command:
cat Ray-RLLib-Tutorials.tar.gz.* | tar xzvf -;
To clean up both the remote Server and our Local PC, we issued the following command:
rm Ray-RLLib-Tutorials.tar.gz.*;
This is a guide on how to download a very big
Jupyterworkspace by splitting it to multiple smaller files using the console.


